Golang编程谚语(Proverbs)中有这么一句:
Don’t communicate by sharing memory, share memory by communicating.
即:不要使用共享内存通信,用通信来实现数据的共享。
首先 Go 的并发原语 (goroutines 和 channels) 为构造并发软件提供了一种优雅而独特的手段. Go 鼓励使用 channels 在 goroutines 之间传递对数据的拷贝, 而不是显式地使用锁来调解对共享数据的访问. 这种方法确保只有一个 goroutine 可以在给定的时间访问数据。
本质上讲,无论是线程还是协程同步信息的方式其实都是「共享内存」,两种方式都离不开从内存获取信息,所以更为准确的说法是「为什么我们使用发送消息的方式来同步信息,而不是多个线程或者协程直接共享内存?』
设计思想
更高的抽象层级
共享内存和消息传递,本质上是传递信息的两种不同抽象层级的实现。
更为高级和抽象的信息传递方式其实也只是对低抽象级别接口的组合和封装,Go 中的 Channel 在内部实现时就广泛用到了共享内存和锁,通过对两者进行的组合提供了更高级的同步机制。
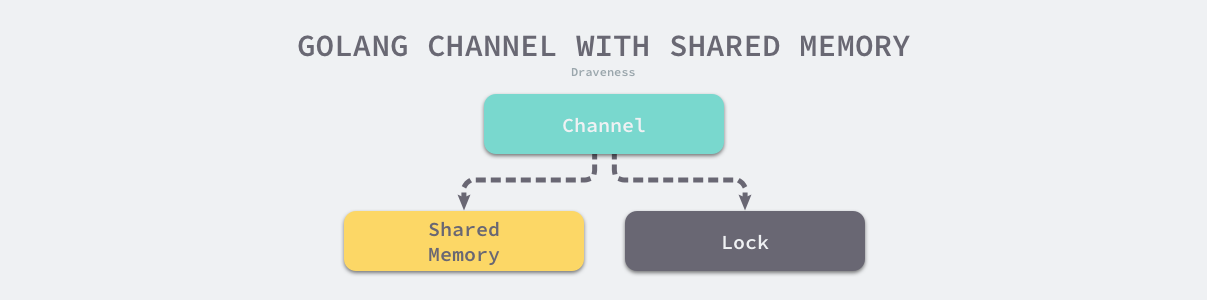
既然两种方式都能够帮助我们在不同的线程或者协程之间传递信息,那么我们应该尽量使用抽象层级更高的方法,因为这些方法往往提供了更良好的封装和与领域更相关和契合的设计;只有在高级抽象无法满足我们需求时才应该考虑抽象层级更低的方法,例如:当我们遇到对资源进行更细粒度的控制或者对性能有极高要求的场景。
更低的耦合
这条角度其实可以和另一条Go谚语放到一起理解
Channels orchestrate; mutexes serialize
Channel重排列,Mutex重串行
通过使用发送消息的方式替代共享内存能够帮助我们减少多个模块之间的耦合。
如何理解呢?
下面我们使用共享内存和发送消息两种模式,实现保存一场游戏玩家分数最大值的程序。
共享内存
type Game struct {
mtx sync.Mutex
bestScore int
}
func NewGame() *Game {
return &Game{}
}
func (g *Game) HandlePlayer(p Player) error {
for {
score, err := p.NextScore()
if err != nil {
return err
}
g.mtx.Lock()
if g.bestScore < score {
g.bestScore = score
}
g.mtx.Unlock()
}
}
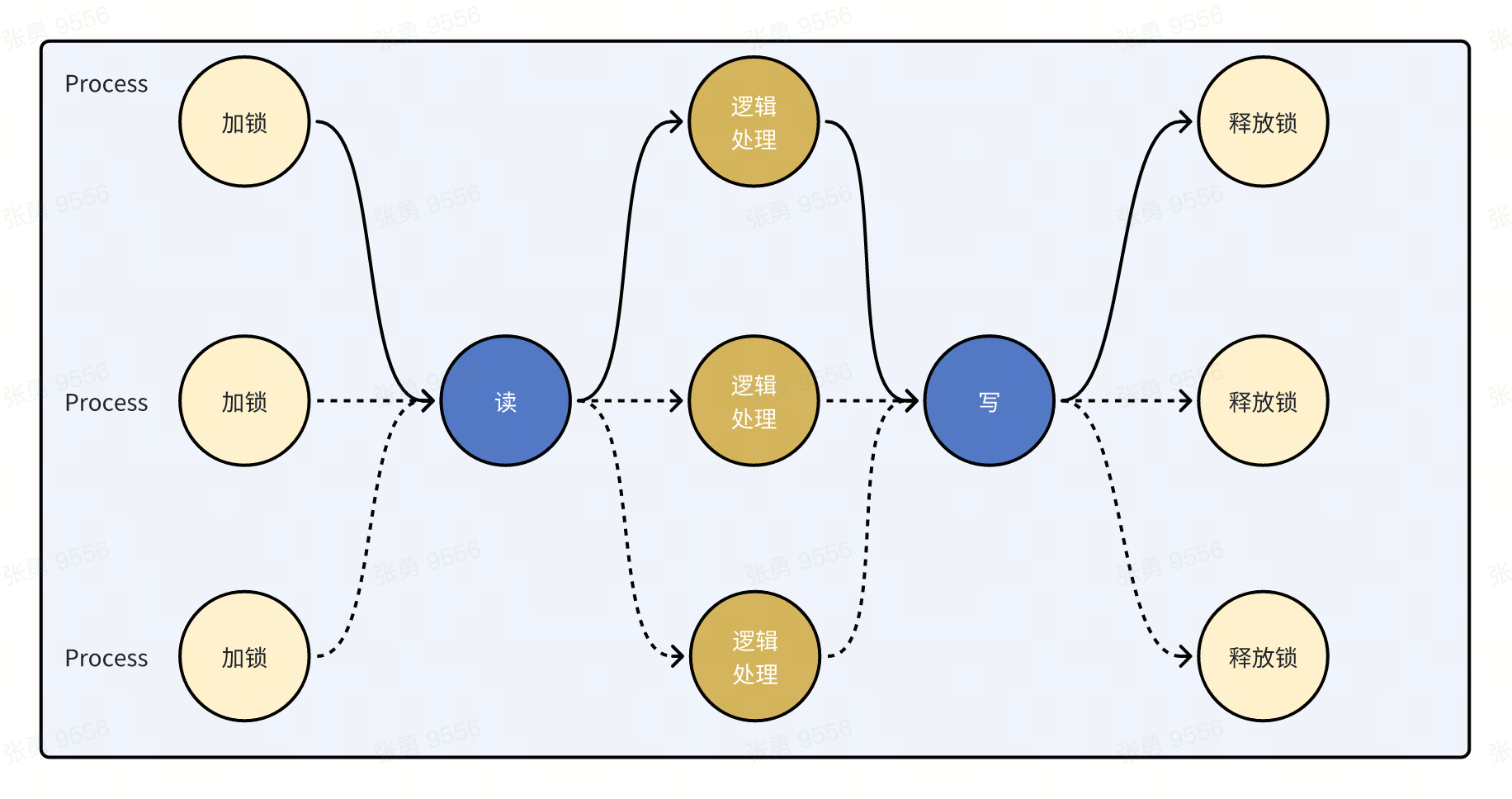
在共享内存模式下,我们只需关注数据,要求同一时刻只有一方可以对数据进行读写访问,所有对数据的处理逻辑是在整个流程中顺序进行的。
即:加锁->读->逻辑处理->写->释放锁
上面的流程可以被多个 进程/线程/协程 并发执行
发送消息
type Game struct {
bestScore int
scores chan int
}
// 消费者
func (g *Game) run() {
for score := range g.scores {
if g.bestScore < score {
g.bestScore = score
}
}
}
func NewGame() (g *Game) {
g = &Game{
bestScore: 0,
scores: make(chan int),
}
go g.run()
return g
}
type Player interface {
NextScore() (score int, err error)
}
// 可以实例化多个Player模拟生产者
func (g *Game) HandlePlayer(p Player) error {
for {
score, err := p.NextScore()
if err != nil {
return err
}
g.scores <- score
}
}
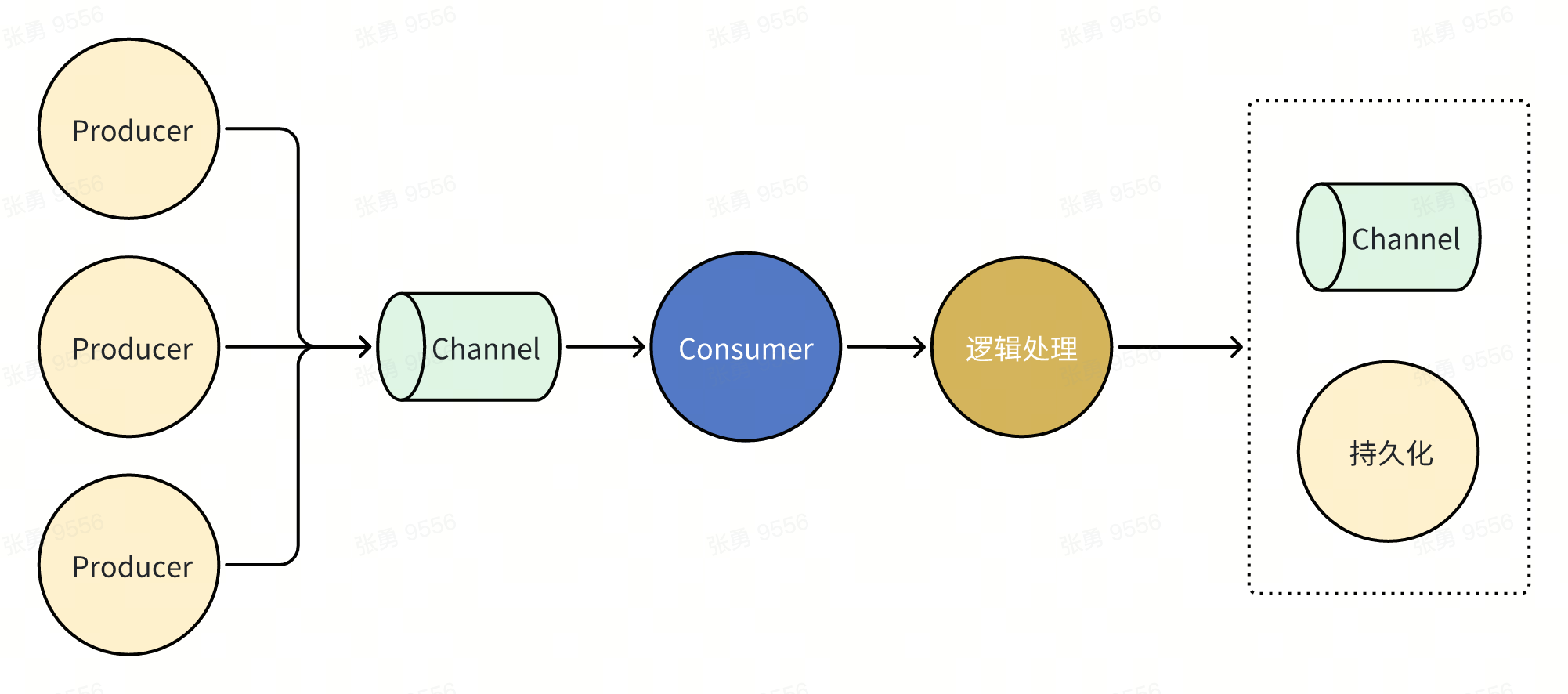
在发送消息模式下,不仅关注数据本身,还关注数据的方向(流向)。
需要将整个过程拆分为生产者和消费者,通过channel协调数据的方向,进行「编排」。
即:
生产者->Channel
Channel->消费者->逻辑处理->写
上面的流程可以有多个生产者,一个消费者消费即可
(Go语言在Channel的实现方式上保证了同一时间只有一方能获取到数据,从设计上天然地避免线程竞争和数据冲突的问题)
使用两个Goroutine交替打印100以内的奇偶数
func printEven(evenCh, oddCh chan struct{}, wg *sync.WaitGroup) {
defer wg.Done()
for i := 0; i <= 100; i += 2 {
<-evenCh // 等待信号
fmt.Println(i)
oddCh <- struct{}{} // 发送信号
}
}
func printOdd(evenCh, oddCh chan struct{}, wg *sync.WaitGroup) {
defer wg.Done()
for i := 1; i <= 100; i += 2 {
<-oddCh // 等待信号
fmt.Println(i)
evenCh <- struct{}{} // 发送信号
}
}
func TestPrintNum(t *testing.T) {
var wg sync.WaitGroup
evenCh := make(chan struct{}, 1)
oddCh := make(chan struct{}, 1)
wg.Add(2)
go printEven(evenCh, oddCh, &wg)
go printOdd(evenCh, oddCh, &wg)
evenCh <- struct{}{} // 开始打印偶数
wg.Wait()
}
经验教训
之前项目有这么个需求:异步删除聊天群组的成员。
实现上,我们提供asyncDelGroupMembers接口用于业务方异步调用,在服务端使用协程启动定时Job每XX时间执行删除操作。
异步接口和定时Job之间使用共享内存和锁的机制进行数据同步。
上线后运行起来一直比较平稳,直到有一天,定时Job执行删除操作由于某些原因卡住了,这时由于锁机制的存在导致生产数据的异步接口也被卡住,从而造成业务客户端timeout重试,最后就是这个问题的雪崩,超时请求越来越多,定时job处理也越来越慢,恶性循环。
异步接口和定时Job的伪代码如下:
// asyncDelGroupMembers 接口
func AsyncDelGroupMembersHandler(c echo.Context) error {
....
DGM.Mutex.Lock()
defer DGM.Mutex.Unlock()
if _, ok := DGM.Data[projectID]; !ok {
DGM.Data[projectID] = make(map[int64][]int64)
}
DGM.Data[projectID][groupID] = append(DGM.Data[projectID][groupID], uid)
}
// 异步定时job
func aggregateDel() {
DGM.Mutex.Lock()
defer DGM.Mutex.Unlock()
for projectID, item := range DGM.Data {
...
for groupID, uidList := range item {
... 执行真正的批量Del逻辑
}
// clear
DGM.Data[projectID] = make(map[int64][]int64)
}
}
所以,从上面的伪代码我们可以看出,真正导致问题出现的原因有两个:
- 异步Job的锁范围太大,一旦出现问题就会长时间锁住不放
- 消费者(Job)的超时问题通过共享内存和锁机制传导到了生产者(异步接口)上
因为,后续我们使用channel代替了共享内存+锁机制,对生产者和消费者进行解耦来解决此问题。
参考
为什么使用通信来共享内存
Share Memory By Communicating
Go channels are bad and you should feel bad
诠释 Channels orchestrate; mutexes serialize
https://www.zhihu.com/question/58004055