之前写过一篇文章 《关于对「Don’t communicate by sharing memory, share memory by communicating」的理解》 ,在里面介绍了我对Golang CSP设计理念中「通信」概念的理解。
所以,与前者不同的是,本篇更注重Channel相关底层实现的探索。
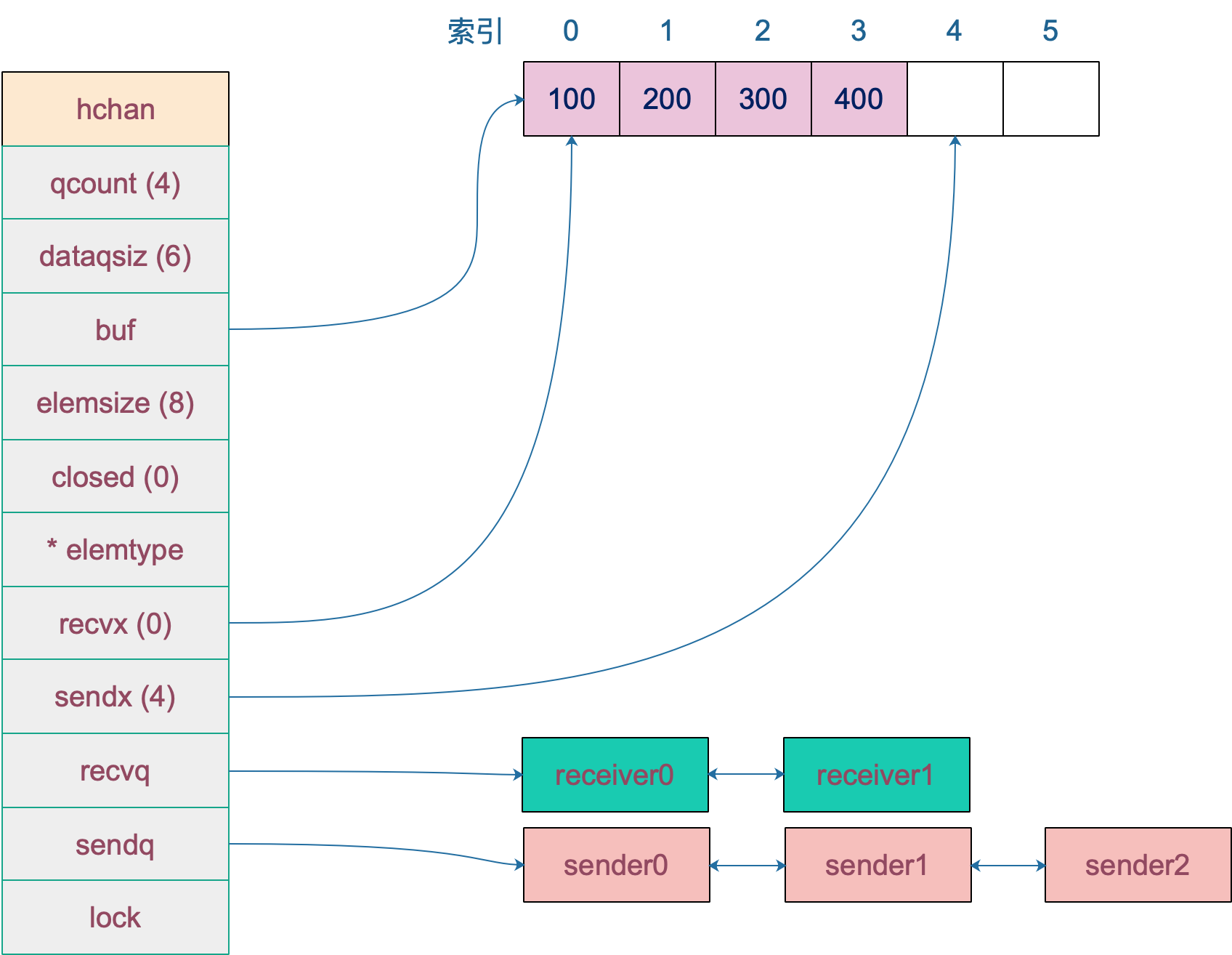
数据结构
type hchan struct {
qcount uint // 当前队列中的元素数量
dataqsiz uint // chan 底层循环数组的长度
buf unsafe.Pointer // 指向底层循环数组的指针,只针对有缓冲的 channel
elemsize uint16 // chan 中元素大小
closed uint32 // chan 是否已关闭
elemtype *_type // 元素的类型信息
sendx uint // 发送索引
recvx uint // 接收索引
recvq waitq // 等待接收的 goroutine 队列
sendq waitq // 等待发送的 goroutine 队列
lock mutex // 互斥锁,保护 channel 的并发访问
}
重点说明:
- 对于非缓冲channel,
buf字段为 nil,dataqsiz为 0。 发送和接收操作不会使用buf,而是直接通过sendq和recvq队列进行同步。 当发送操作发生时,如果recvq队列中有等待的接收者,数据会直接从发送者拷贝到接收者,反之亦然。 sendx,recvx均指向底层循环数组,表示当前可以发送和接收的元素位置索引值(相对于底层数组)。sendq,recvq分别表示被阻塞的 goroutine,这些 goroutine 由于尝试读取 channel 或向 channel 发送数据而被阻塞。waitq是sudog的一个双向链表,而sudog实际上是对 goroutine 的一个封装
type waitq struct {
first *sudog
last *sudog
}
- lock 用来保证每个读 channel 或写 channel 的操作都是原子的。
创建一个容量为 6 的,元素为 int 型的 channel 数据结构如下 :
Channel的阻塞模式和非阻塞模式
阻塞模式
在阻塞模式下,通道的发送和接收操作会导致当前 goroutine 被阻塞,直到操作可以成功完成,例如
ch <- value // 发送操作会阻塞,直到有空间可用
value := <-ch // 接收操作会阻塞,直到有数据可读
非阻塞模式
在非阻塞模式下,通道的发送和接收操作不会导致 goroutine 被阻塞,而是会立即返回一个结果。 例如使用 select 语句结合 default 分支来实现
select {
case ch <- value: // 尝试发送值
// 发送成功
default:
// 通道已满,发送失败,不会阻塞
}
select {
case value := <-ch: // 尝试接收值
// 接收成功
default:
// 通道为空,接收失败,不会阻塞
}
Channel数据操作
向Channel发送数据
发送过程涉及到go源码的 chansend 函数,位于 src/runtime/chan.go 文件。
代码咱就不看了,来看看涉及到的主要流程。
- 阻塞模式下,如果检测到
channel是 nil ,当前goroutine会被挂起。 - 非阻塞模式下,如果
channel未关闭并且没有多余的缓冲空间,直接返回false。 - 如果检测到
channel已经关闭,直接panic。 - 如果能从等待接收队列
recvq里出队一个sudog(代表一个goroutine),说明此时channel是空的,没有元素,所以才会有等待接收者。这时会调用send函数将元素直接从发送者的栈拷贝到接收者的栈(无缓冲chan,不用先拷贝到buf,直接由发送者到接收者,效率得以提高) - 如果
c.qcount<c.dataqsiz,说明缓冲区可用(肯定是缓冲型的channel)。先通过函数取出待发送元素应该去到的位置。c.sendx指向下一个待发送元素在循环数组中的位置,然后调用typedmemmove函数将其拷贝到循环数组中。之后c.sendx加 1,元素总量加 1 :c.qcount++,最后,解锁并返回。 - 如果没有命中以上条件的,说明
channel已经满了。不管这个channel是缓冲型的还是非缓冲型的,都要将这个goroutine被阻塞。如果 非阻塞模式直接解锁,返回 false。 - 阻塞模式下先构造一个
sudog,将其入队(channel的sendq字段)。然后调用goparkunlock将当前goroutine挂起,并解锁,等待合适的时机再唤醒。 所以,待发送的元素地址其实是存储在sudog结构体里,也就是当前goroutine里。
向Channel接收数据
接收操作有两种写法,一种带 “ok”,反应 channel 是否关闭;一种不带 “ok”,这种写法,当接收到相应类型的零值时无法知道是真实的发送者发送过来的值,还是 channel 被关闭后,返回给接收者的默认类型的零值。两种写法,都有各自的应用场景。
接收过程对应的是在源码 src/runtime/chan.go 文件里的 chanrecv 函数。
主要流程如下:
- 如果 channel 是一个空值(nil),在非阻塞模式下,会直接返回。在阻塞模式下,会调用 gopark 函数挂起 goroutine,这个会一直阻塞下去。因为在 channel 是 nil 的情况下,要想不阻塞,只有关闭它,但关闭一个 nil 的 channel 又会发生 panic,所以没有机会被唤醒了。
- 非阻塞模式下,如果
channel未关闭并且(非缓冲型,等待发送列队里没有 goroutine 在等待或者缓冲型,但 buf 里没有元素)直接返回false - 接下来的,如果 channel 已关闭,并且循环数组 buf 里没有元素。对应非缓冲型关闭和缓冲型关闭但 buf 无元素的情况,返回对应类型的零值,但 received 标识是 false,告诉调用者此 channel 已关闭,你取出来的值并不是正常由发送者发送过来的数据。
- 接下来,如果有等待发送的队列,说明 channel 已经满了,要么是非缓冲型的 channel,要么是缓冲型的 channel,但 buf 满了。这两种情况下都可以正常接收数据。
- 对于缓冲型 channel,而 buf 又满了的情形。说明发送游标和接收游标重合了,因此需要先找到接收游标。将该处的元素拷贝到接收地址。然后将发送者待发送的数据拷贝到接收游标处。这样就完成了接收数据和发送数据的操作。
- 然后,如果 channel 的 buf 里还有数据,说明可以比较正常地接收。注意,这里,即使是在 channel 已经关闭的情况下,也是可以走到这里的。这一步比较简单,正常地将 buf 里接收游标处的数据拷贝到接收数据的地址,函数return。
- 到了最后一步,走到这里来的情形是要阻塞的。当然,如果 block 传进来的值是 false,那就不阻塞,直接返回就好了。
Channel操作数据的本质
channel 的发送和接收操作本质上都是 “值的拷贝”,无论是从 sender goroutine 的栈到 chan buf,还是从 chan buf 到 receiver goroutine,或者是直接从 sender goroutine 到 receiver goroutine。
Channel会引起资源泄漏吗?
有一种特殊情况,比如当 goroutine 操作 channel 后,处于发送或接收阻塞状态,而 channel 处于满或空的状态,一直得不到改变。同时,垃圾回收器也不会回收此类资源,进而导致 gouroutine 会一直处于等待队列中,进而引发资源泄漏。
总结
| 操作 | nil channel | closed channel | not nil, not closed channel |
|---|---|---|---|
| close | panic | panic | 正常关闭 |
| 读 <- ch | 阻塞 | 读到对应类型的零值 | 阻塞或正常读取数据。缓冲型 channel 为空或非缓冲型 channel 没有等待发送者时会阻塞 |
| 写 ch <- | 阻塞 | panic | 阻塞或正常写入数据。非缓冲型 channel 没有等待接收者或缓冲型 channel buf 满时会被阻塞 |
发生 panic 的情况有三种:
- 向一个关闭的 channel 进行写操作
- 关闭一个 nil 的 channel
- 重复关闭一个 channel
关闭Channel
close 逻辑比较简单,对于一个 channel,recvq 和 sendq 中分别保存了阻塞的发送者和接收者。关闭 channel 后,对于等待接收者而言,会收到一个相应类型的零值。对于等待发送者,会直接 panic。所以,在不了解 channel 还有没有等待发送者的情况下,不能贸然关闭 channel。
close 函数先上一把大锁,接着把所有挂在这个 channel 上的 sender 和 receiver 全都连成一个 sudog 链表,再解锁。最后,再将所有的 sudog 全都唤醒。
唤醒之后,该干嘛干嘛。
sender 会继续执行 chansend 函数里 goparkunlock 函数之后的代码,很不幸,检测到 channel 已经关闭了,panic。receiver 则比较幸运,进行一些扫尾工作后返回。
从关闭的Channel还能读出数据吗
从一个有缓冲的 channel 里读数据,当 channel 被关闭,依然能读出有效值(与此同时ok状态依然为true)。
只有在 channel 被关闭且缓冲区没有数据时,返回的 ok 为 false ,读出的数据才是无效的。
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int, 2)
go func() {
ch <- 1
ch <- 2
close(ch) // 关闭 channel
}()
time.Sleep(time.Second) // 确保数据发送完成
for {
select {
case value, ok := <-ch:
if !ok {
fmt.Println("Channel is closed")
return
}
fmt.Println("Received:", value)
default:
fmt.Println("No data available")
time.Sleep(500 * time.Millisecond)
}
}
}
运行结果:
Received: 1
Received: 2
Channel is closed
如何优雅地关闭
最本质的原则就只有一条:
don’t close (or send values to) closed channels.
根据 sender 和 receiver 的个数,分下面几种情况:
- 一个 sender,一个 receiver
- 一个 sender, M 个 receiver
- N 个 sender,一个 reciver
- N 个 sender, M 个 receiver
对于 1,2,只有一个 sender 的情况就不用说了,直接从 sender 端关闭就好了,没有问题。重点关注第 3,4 种情况。
第 3 种情形下,解决方案就是增加一个传递关闭信号的 channel,receiver 通过信号 channel 下达关闭数据 channel 指令。senders 监听到关闭信号后,停止发送数据。
代码如下:
func main() {
rand.Seed(time.Now().UnixNano())
const Max = 100000
const NumSenders = 1000
dataCh := make(chan int, 100)
stopCh := make(chan struct{})
// senders
for i := 0; i < NumSenders; i++ {
go func() {
for {
select {
case <- stopCh:
return
case dataCh <- rand.Intn(Max):
}
}
}()
}
// the receiver
go func() {
for value := range dataCh {
if value == Max-1 {
fmt.Println("send stop signal to senders.")
close(stopCh)
return
}
fmt.Println(value)
}
}()
select {
case <- time.After(time.Hour):
}
}
需要说明的是,上面的代码并没有明确关闭 dataCh。在 Go 语言中,对于一个 channel,如果最终没有任何 goroutine 引用它,不管 channel 有没有被关闭,最终都会被 gc 回收。所以,在这种情形下,所谓的优雅地关闭 channel 就是不关闭 channel,让 gc 代劳。
最后一种情况,这里有 M 个 receiver,如果直接还是采取第 3 种解决方案,由 receiver 直接关闭 stopCh 的话,就会重复关闭一个 channel,导致 panic。因此需要增加一个中间人,M 个 receiver 都向它发送关闭 dataCh 的“请求”,中间人收到第一个请求后,就会直接下达关闭 dataCh 的指令(通过关闭 stopCh,这时就不会发生重复关闭的情况,因为 stopCh 的发送方只有中间人一个)。另外,这里的 N 个 sender 也可以向中间人发送关闭 dataCh 的请求。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
dataCh := make(chan int, 10)
stopChan := make(chan struct{}) // 用于通知所有sender停止
var wg sync.WaitGroup
// 安全关闭函数
closeDataCh := func() {
select {
case <-stopChan: // 已经关闭
default:
close(stopChan) // 通知所有sender停止
}
}
// 启动sender
for i := 0; i < 3; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
for j := 0; ; j++ {
value := id*1000 + j
select {
case dataCh <- value:
fmt.Printf("sender %d sent: %d\n", id, value)
case <-stopChan: // 收到停止信号
fmt.Printf("sender %d received stop signal\n", id)
return
}
}
}(i)
}
// 启动receiver
for i := 0; i < 2; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
for {
select {
case data, ok := <-dataCh:
if !ok {
fmt.Printf("receiver %d: dataCh closed\n", id)
return
}
fmt.Printf("receiver %d received: %d\n", id, data)
// 达到条件时触发关闭流程
if data > 100 {
fmt.Printf("receiver %d detected data > %d, initiating shutdown\n", id, maxData)
closeDataCh()
}
case <-stopChan:
fmt.Printf("receiver %d received stop signal\n", id)
return
}
}
}(i)
}
wg.Wait()
}
Channel应用
停止信号
package main
import (
"fmt"
"time"
)
func worker(done chan struct{}) {
fmt.Println("Working...")
... // 模拟工作
fmt.Println("Done")
close(done) // 关闭 channel 作为通知信号
}
func main() {
done := make(chan struct{})
go worker(done)
<-done // 等待 channel 关闭
fmt.Println("Worker finished, main exiting")
}
定时任务
select {
case <-time.After(100 * time.Millisecond):
case <-s.stopc:
return false
}
等待 100 ms 后,如果 s.stopc 还没有读出数据或者被关闭,就直接结束。这是来自 etcd 源码里的一个例子,这样的写法随处可见。
解耦生产方和消费方
服务启动时,启动 n 个 worker,作为工作协程池,这些协程工作在一个 for {} 无限循环里,从某个 channel 消费工作任务并执行:
func main() {
taskCh := make(chan int, 100)
go worker(taskCh)
// 塞任务
for i := 0; i < 10; i++ {
taskCh <- i
}
// 等待 1 小时
select {
case <-time.After(time.Hour):
}
}
func worker(taskCh <-chan int) {
const N = 5
// 启动 5 个工作协程
for i := 0; i < N; i++ {
go func(id int) {
for {
task := <- taskCh
fmt.Printf("finish task: %d by worker %d\n", task, id)
time.Sleep(time.Second)
}
}(i)
}
}
5 个工作协程在不断地从工作队列里取任务,生产方只管往 channel 发送任务即可,解耦生产方和消费方。
控制并发数
有时需要定时执行几百个任务,例如每天定时按城市来执行一些离线计算的任务。但是并发数又不能太高,因为任务执行过程依赖第三方的一些资源,对请求的速率有限制。这时就可以通过 channel 来控制并发数。
下面的例子来自《Go 语言高级编程》:
var limit = make(chan int, 3)
func main() {
// …………
for _, w := range work {
go func() {
limit <- 1
w()
<-limit
}()
}
// …………
}
构建一个缓冲型的 channel,容量为 3。接着遍历任务列表,每个任务启动一个 goroutine 去完成。真正执行任务,访问第三方的动作在 w() 中完成,在执行 w() 之前,先要从 limit 中拿“许可证”,拿到许可证之后,才能执行 w(),并且在执行完任务,要将“许可证”归还。这样就可以控制同时运行的 goroutine 数。
这里,limit <- 1 放在 func 内部而不是外部,原因是:
- 如果在外层,就是控制系统 goroutine 的数量,可能会阻塞 for 循环,影响业务逻辑。
- limit 其实和逻辑无关,只是性能调优,放在内层和外层的语义不太一样。
还有一点要注意的是,如果 w() 发生 panic,那“许可证”可能就还不回去了,因此需要使用 defer 来保证。
参考
https://golang.design/go-questions/channel/send/
https://golang.design/go-questions/channel/recv/