上篇文章提到了Context在OpenTelemetry-Go中的应用
其中的经验来自于之前工作中对公司内部分布式服务做链路追踪的经历,所以这篇文章来做分布式链路追踪的实践回顾。
私有规范
最开始接触是公司准备针对内网微服务间的调用来做链路追踪,想法来自于Google的那篇著名文章《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》
文章主要介绍Google内部使用Dapper来监控分布式系统的性能和异常问题,并介绍以下概念和实现细节:
- 使用TraceID来唯一标识一次请求,可以把TraceID当作一棵Trace链路追踪树的唯一ID
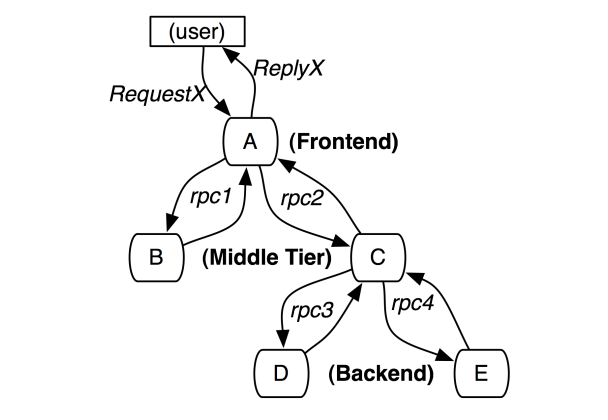
- 使用Span来表示分布式链路中每个工作单元,一个Span即Trace树的一个节点。
- 每个span都有一个唯一的span ID和一个父span ID,用于构建链路调用结构(数/瀑布图)。没有父span ID的span称为根span。
- 使用采样率对应用服务进行指标采集,从而实现低开销接入,避免因引入Dapper造成业务性能影响。
the tracing system should have negligible performance impact on running services. In some highly optimized services even small monitor- ing overheads are easily noticeable, and might compel the deployment teams to turn the tracing system off
- Dapper通过hook常见库行为来实现业务无感知接入,如基础RPC、线程和控制流库。
Perhaps the most critical part of Dapper’s code base is the instrumentation of basic RPC, threading and control flow libraries, which includes span creation, sampling, and logging to local disks.
在介绍我们私有化实现Trace架构的细节之前,有必要针对当时公司内部微服务架构的特点进行一些说明:
- 内部微服务以HTTP Restful API调用为主,主要集中在各业务模块间如商场、主页、支付等。
- 所有的服务端请求都会经过两大网关(OpenResty开发,易定制化插件),分别处理来自外部的请求和内部微服务间请求。
- 服务端框架以PHP、Go两种语言为主,自研和开源均有涉及。
- 客户端、服务端、网关日志统一上报至日志中心,做后续检索、监控和实时/离线计算等处理。
所以针对上述特点和对Dapper的理解,我们实现了第一版私有化Trace链路追踪架构:
- 节点间关系只有两种:ChildOf 和 FollowBy
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C is a `ChildOf` Span A)
|
+---+-------+
| |
[Span D] [Span E] >>> [Span F]
↑
↑
↑
(Span F `FollowBy` Span E)
- 针对所有经过统一网关的HTTP请求,我们和网关伙伴合作通过制定以下规范
- 所有经过网关的请求透传HTTP Header里的Trace ID和Span ID
- 网关服务在请求HTTP Header里识别Trace ID
- 初始TraceID由客户端生成,如果没有携带则由网关补充
- TraceID生成规则:毫秒级时间戳+IP(16进制)+进程ID+自增序列
- 网关服务在请求HTTP Header里识别Span ID
- 如果没有则生成根Span即:“1”,有则透传
- 应用服务框架通过支持私有规范的组件自行对SpanID进行管理
- 对Span ID进行迭代,在原有基础上追加尾部序列号,如"1"->“1.1”,“1.2”->“1.2.1"等,以此维护 ChildOf 关系
- 对Span ID最后一位进行巡署迭代,如"1.1”->“1.2”,“1.2.2”->“1.2.3”,以此维护 FollowBy 关系
- Trace日志除必要的TraceID、SpanID数据外也可自定义添加如HTTP code码,调用延迟等数据
- 无论网关日志还是服务端日志,最终都会通过日志采集进入Trace日志存储模块来检索、告警
- 当Trace下的SpanID都为初始1时,按照请求时间排序展示
- 需要服务端配合在HTTP Header里透传Trace数据,以保持整条链路完整统一。但由于服务端框架太杂难以统一,无法像Google那样通过hook底层库来实现无侵入式接入,所以我们采用两种策略
- 自研框架通过升级HTTP SDK支持
- 其余框架需要业务配合在代码中兼容携带
最终上面的调用示例对应的Trace链路图为:
TraceID: 3155760000000C0A80001655350000
[Span A] ←←← SpanID:1
|
+------+------+
| |
[Span B] [Span C] ←←← SpanID:1.2
↑ |
SpanID:1.1 +---+-------+
| |
[Span D] [Span E] >>> [Span F]
↑ ↑ ↑
SpanID:1.2.1 SpanID:1.2.2 SpanID:1.2.3
OpenTelemetry开源规范
上面的私有规范在运行一段时间后普遍集中几个问题:
- 业务方想接入Grpc服务,但当前架构只支持HTTP服务
- 本质上无法在底层无侵入的管理Trace数据,需要业务升级或接入开发,推广起来有难度
后来在了解到有的业务自行基于OpenTracing规范接入开源组件进行监控后,我们决定兼容这些使用grpc以及已接入OpenTracing的服务。
最终我们通过使用OpenTelemetry+Tempo+Grafana的方式统一接收开源Trace数据并进行监控和展示。
我在Github上创建了一个使用Docker-compose来快速搭建这套系统的Demo仓库,里面有基于Grpc实现的业务代码,按照仓库说明运行即可,帮助读者快速理解和使用。
地址:https://github.com/zonghay/Trace-For-Otel-Tempo-Grafana-Demo
OpenTelemetry
OpenTelemetry(OTel)和 OpenTelemetry-Collector(OTel-Collector)是 OpenTelemetry 生态中的两个核心组件。OTel 负责数据的采集和标准化,而 OTel Collector 负责数据的接收、处理和导出。
OTel提供多种语言的SDK或者自动插桩的方式(Java Agent;HTTP、Grpc拦截器),来生成和传播 Trace 数据,如 Span 和 Trace ID。最终通过导出器(Exporter)将采集到的 Trace 数据导出到后端存储系统(如 OTel-Collector、Jaeger、Zipkin 等)
OTel的优势:
- 标准化:OTel 是 CNCF(云原生计算基金会)项目,旨在成为观测性数据的标准
- 多语言支持:支持多种编程语言,适用于异构的分布式系统
- 灵活性:可以通过手动插桩或自动插桩采集数据,并支持多种后端存储
比如在Demo仓库中,我们就是通过在Grpc Client和Server中引入Grpc拦截器来生成请求Trace数据。
// grpc server
func main() {
// 初始化 OpenTelemetry
cleanup := initTracer()
defer cleanup()
lis, err := net.Listen("tcp", port)
if err != nil {
log.Fatalf("Failed to listen: %v", err)
}
// 创建 gRPC 服务器并添加 OpenTelemetry 拦截器
s := grpc.NewServer(
grpc.UnaryInterceptor(otelgrpc.UnaryServerInterceptor()),
grpc.StreamInterceptor(otelgrpc.StreamServerInterceptor()),
)
pb.RegisterGreeterServer(s, &server{})
log.Printf("Server started on %v", port)
if err := s.Serve(lis); err != nil {
log.Fatalf("Failed to serve: %v", err)
}
}
OpenTelemetry Collector
OpenTelemetry-Collector 是一个独立的组件,用于接收、处理和转发遥测数据。它支持多种数据格式和协议,可以作为数据管道的中心枢纽。
OTel-Collector 的核心组件:
- Receivers:接收来自不同来源的遥测数据(如 OTLP、Jaeger、Zipkin 等)
- Processors:对接收到的数据进行处理(如过滤、转换、采样等)
- Exporters:将处理后的数据导出到后端存储系统(如 Tempo、Jaeger等)
OTel-Collector 的优势:
- 多数据格式支持:支持多种 Trace 数据格式(如 OTLP、Jaeger、Zipkin 等)
- 灵活的数据处理:通过配置处理器(Processors)实现数据的过滤、转换和采样
- 水平扩展:可以水平扩展以处理大规模的遥测数据
在Demo中我们需要在服务启动时创建负责接受Trace数据的OTel-Collector对象
// 初始化 OpenTelemetry
func initTracer() func() {
ctx := context.Background()
// 创建 OTLP exporter,增加超时和重试选项
exporter, err := otlptracegrpc.New(ctx,
otlptracegrpc.WithInsecure(),
otlptracegrpc.WithEndpoint("localhost:4317"),
otlptracegrpc.WithTimeout(10*time.Second), // 增加超时时间
otlptracegrpc.WithRetry(otlptracegrpc.RetryConfig{
Enabled: true,
InitialInterval: 500 * time.Millisecond,
MaxInterval: 5 * time.Second,
MaxElapsedTime: 30 * time.Second,
}),
)
if err != nil {
log.Fatalf("Failed to create OTLP exporter: %v", err)
}
// 创建资源
res, err := resource.New(ctx,
resource.WithAttributes(
semconv.ServiceName("grpc-server"),
semconv.ServiceVersion("1.0.0"),
semconv.TelemetrySDKLanguageGo,
),
)
if err != nil {
log.Fatalf("Failed to create resource: %v", err)
}
// 创建 trace provider
tp := sdktrace.NewTracerProvider(
sdktrace.WithSampler(sdktrace.AlwaysSample()),
sdktrace.WithBatcher(exporter),
sdktrace.WithResource(res),
)
otel.SetTracerProvider(tp)
otel.SetTextMapPropagator(propagation.NewCompositeTextMapPropagator(propagation.TraceContext{}, propagation.Baggage{}))
return func() {
if err := tp.Shutdown(ctx); err != nil {
log.Fatalf("Failed to shutdown tracer provider: %v", err)
}
}
}
Tempo
Tempo 是 Grafana Labs 开发的一个开源的分布式追踪后端,专注于高效存储和查询大规模的 Trace 数据。Tempo 的设计目标是低成本、高性能,并且能够与 Grafana 无缝集成。
Tempo 的优势:
- 低成本:使用对象存储作为后端,降低了存储成本。
- 高性能:通过 Trace ID 直接查询,避免了复杂的索引和查询逻辑。
- 易集成:与 Grafana 无缝集成,提供强大的可视化能力。
- 兼容性:支持 OpenTelemetry、Jaeger、Zipkin 等多种数据格式。
Grafana展示效果
在Grafana内Import仓库里提供的grafana_template.json文件自动生成链路追踪的DashBoard(更多Tempo Dashboard可在Grafana官方市场查找Grafana dashboards)
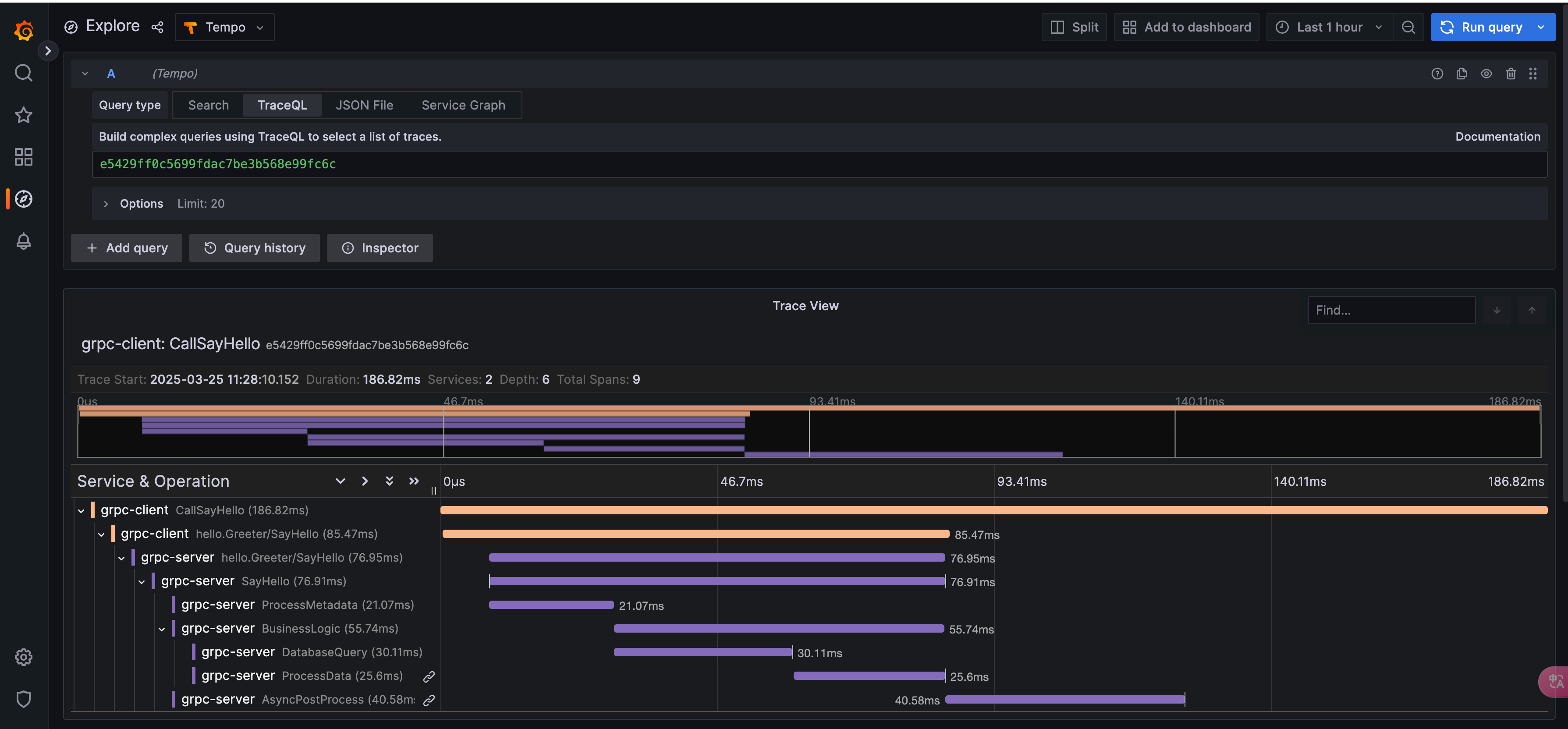
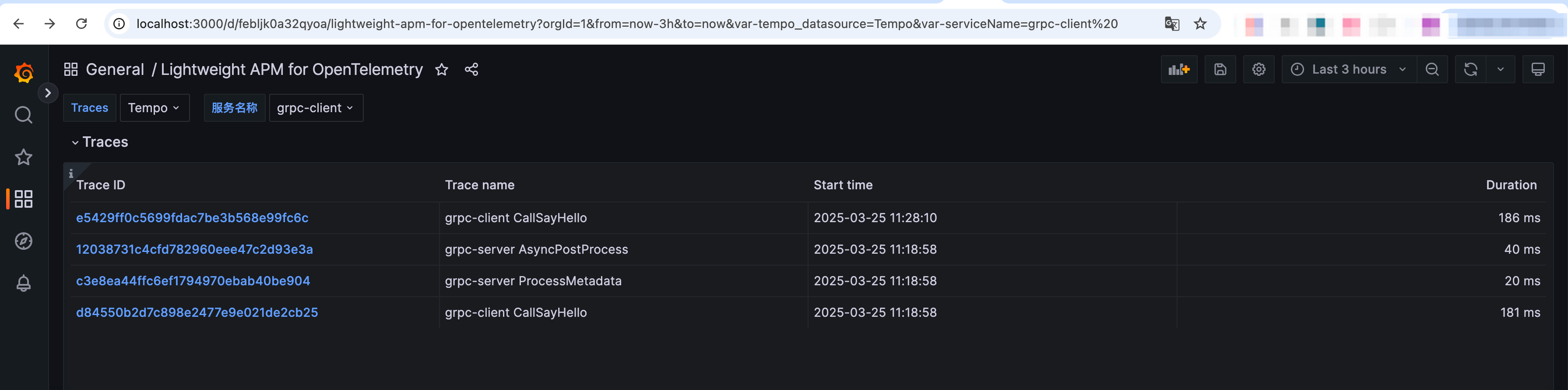 点击Dashboard中的TraceId链接,即可跳转到对应仓库代码调用链路的Trace瀑布图(代码运行可参考仓库ReadMe文件)。
点击Dashboard中的TraceId链接,即可跳转到对应仓库代码调用链路的Trace瀑布图(代码运行可参考仓库ReadMe文件)。
参考仓库代码grpc/server/main.go代码
参考
阿里云-可观测链路OpenTelemetry版
How to send traces to Grafana Cloud’s Tempo service with OpenTelemetry Collector
Grafana Tempo
OTel-Collector