曾经听前同事讲过一句话「PHP的精髓是他的数组」。
彼时年龄和经验都尚浅,对这句话体会不是很深。但自从开始写golang,我是越来越怀念PHP数组那种简单、粗暴的,不管三七二十一,拿来直接往里面塞的编码体验了。
于是,便有了这篇探索PHP到底是如何实现这个能够「容纳万物」的数据类型的文章。
知其然,更要知其所以然。
HashTable定义
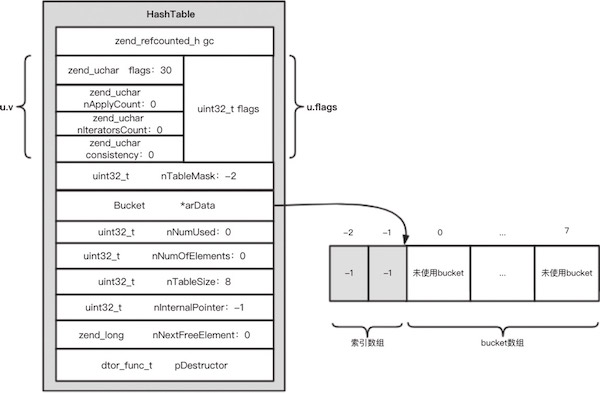
首先,PHP数组底层的数据结构是zend自己用C语言实现的HashTable,而且这个HashTable类型被用在PHP内核的很多地方。
下面是PHP7.4中HashTable的源码定义(php-src/Zend/zend_types.h):
//Bucket:散列表中存储的元素
typedef struct _Bucket {
zval val;
zend_ulong h; /* hash value (or numeric index) */
zend_string *key; /* string key or NULL for numerics */
} Bucket;
typedef struct _zend_array HashTable;
struct _zend_array {
zend_refcounted_h gc; //这是用于垃圾回收的引用计数头部。所有PHP的zval和复合类型(如数组)都使用了这种结构,以便能够进行引用计数和垃圾收集
union {
struct {
ZEND_ENDIAN_LOHI_4(
uint8_t flags,
uint8_t _unused,
uint8_t nIteratorsCount,
uint8_t _unused2)
} v;
uint32_t flags;
} u; //这是一个联合体,用于以不同的方式访问相同的内存区域。ZEND_ENDIAN_LOHI_4 是一个宏,用于处理不同字节序(大端和小端)的系统。它定义了一个包含四个 uint8_t 类型的匿名结构体,分别对应 flags, _unused, nIteratorsCount, 和 _unused2。同时,整个结构体可以作为一个 uint32_t 类型的 flags 被访问。
union {
uint32_t *arHash; /* hash table (allocated above this pointer) */ //指向哈希表的指针,用于关联数组
Bucket *arData; /* array of hash buckets */ //指向包含键值对的桶数组的指针(存在不连续的索引数组)
zval *arPacked; /* packed array of zvals */ //指向紧密打包的 zval 数组的指针,用于索引数组
}; // 这是存储数组元素的联合体,可以以上面三种不同的形式访问
uint32_t nNumUsed; //表示 arData 中已经使用的 Bucket 数量,包括了可能存在的空洞(已删除的元素)
uint32_t nNumOfElements; //表示哈希表中有效元素的数量,即实际存储在 HashTable 中的元素数量
uint32_t nTableSize; //哈希表的总大小,必须是 2 的幂次方,用于分配 arData 和 arHash
uint32_t nTableMask; //哈希值计算掩码,用于快速计算哈希值在哈希表中的位置,等于 nTableSize 的负值(nTableMask = -nTableSize)
uint32_t nInternalPointer; //当前数组内部指针的位置,用于遍历数组时追踪位置
zend_long nNextFreeElement; //下一个空闲槽索引。例如,当你使用类似 arr[] = 1; 的语法添加元素到数组时,nNextFreeElement 将被用来分配键值,并且在添加后自增。如果还有类似 arr["a"] = 2; arr[] = 3; 的操作,则nNextFreeElement = 2,nNextFreeElement 会跳过任何明确指定的键,并找到下一个可用的数值索引
dtor_func_t pDestructor; //元素的析构函数指针。当一个元素要从 HashTable 中移除时,这个函数会被调用来执行任何必要的清理操作,例如减少引用计数或释放内存。
};
HashTable结构体成员变量重点说明:
- 当将一个元素从哈希表删除时并不会将对应的Bucket移除,而是将Bucket存储的zval修改为IS_UNDEF。并且只将nNumOfElements–
- 另外一个非常重要的值arData,这个值指向存储元素数组的第一个Bucket,插入元素时按顺序 依次插入 数组,比如第一个元素在arData[0]、第二个在arData[1]…arData[nNumUsed]。PHP数组的有序性正是通过arData保证的,这是第一个与普通散列表实现不同的地方。
- arData/arHash只会在插入第一个元素的时候才会被分配内存
- 析构函数如果提供,设置 pDestructor,这是一个回调函数,用于在删除数组元素时释放分配的资源。
 图片摘自于PHP7中数组的一些改进
图片摘自于PHP7中数组的一些改进
Hash函数
hash函数(DJBX33A是PHP用到的一种hash算法)返回的hash值一般是32位或者64位的整型数,这个数有点大,不能直接作为hash数组的索引。
首先通过求余操作将这个数调整到hashtable的大小的范围之内。求余是通过计算hash & (ht->nTableSize - 1),而不是hash % ht->nTableSize,因为ht->nTableSize是2的幂,所以这两种计算的结果是一样的(注意第一种情况用的是与运算&),第二种计算方式需要使用开销更大的整数除法运算。ht->nTableSize -1 的值保存在ht->nTableMask中。
HashTable插入
我们这里以关联数组为例:
- 元素按顺序插入arData中(PHP数组的有序性正是通过arData保证的,这是第一个与普通散列表实现不同的地方),获取元素所在位置idx
- 计算哈希值,根据key的哈希值映射到散列表中的某个位置nIndex,将idx存入这个位置
- 如果nIndex冲突,则放弃更新此处的idx,找到冲突位「前夫哥」在arData中的索引位,将自己的idx位置更新在「前夫哥」Bucket的zval.u2.next值上
- 在散列表中的位置存储nNextFreeElement指向 arData 中新插入 Bucket 的索引
- 增加 nNumOfElements。如果插入的是一个新 Bucket(而不是替换或更新现有的),也增加 nNumUsed。
HashTable查找
查找的流程其实和插入流程的2、3就很像了。
只是如果出现hash冲突的话:
在hash数组中查找索引为idx = ht->arHash[hash & ht->nTableMask]的元素。这个索引对应的元素是冲突处理链表的头元素。所以ht->arData[idx]是我们要检查的第一个元素。如果这个元素中保存的键跟我们要查找的键相同,那么查找就搞定了。
如果不的相同的话,则需要查找冲突处理链表的下一个元素,这个元素的索引保存在bucket->val.u2.next中,它保存在zval结构体中很少会用到的最后4个字节中。我们继续遍历这个链表(使用索引而不是指针)直到找到我们要找的bucket,或者是碰到INVALID_IDX——这意味着你要查找的key并不存在。
注:PHP7相较于PHP5版本在遍历数组方面对于缓存更友好了(cache-friendly),现在是在一段线性的内存地址上进行遍历,而不是在一段内存地址随机的链表上遍历。
HashTable扩容
散列表可存储的value数是固定的,当空间不够用时就要进行扩容了。
PHP散列表的大小为2^n,插入时如果容量不够则首先检查已删除元素所占比例,如果达到阈值(ht->nNumUsed > ht->nNumOfElements + (ht->nNumOfElements » 5),则将已删除元素移除,重建索引,如果未到阈值则进行扩容操作,扩大为当前大小的2倍,将当前Bucket数组复制到新的空间,然后重建索引。
Packed HashTable
PHP中的所有数组都使用了Hashtable。不过在通常情况下,对于连续的、整数索引的数组(真正的数组)而言,这些hash的东西没多大意义。这也是为什么PHP 7中引入了“packed hashtables”这个概念。
在packed hashtables中,arHash数组为NULL,查找只会直接在arData中进行。例如要查找key为5的元素,那么这个元素将是arData[5],或者不存在,没必要再去遍历什么冲突处理链表了。
需要注意的是,即使是整数索引的数组,PHP也必须维持它的顺序。数组[0=>1,1=>2]和数组[1=>2,0=>1]并不是相同。packed hashtable只会作用于键递增的数组,这些数组的key之间可以有间隔,但必须总是递增的。所以如果一个元素以一个”错误“的顺序(例如逆序)插入到数组中,那么packed hashtable就不会被用到。
尽管packed hashtable会带来一些性能上的优化,但它也会存储一些没用的信息。例如我们可以通过bucket的内存地址来确定它的索引值,所以bucket->h是多余的。bucket->key的值永远都是NULL,这些都是浪费内存。
拓展
PHP数组与数据结构
栈
$stack = [];
// 入栈
array_push($stack, "apple"); // $stack[0]="apple"
array_push($stack, "banana");// $stack[1]="banana"
// 出栈
$item = array_pop($stack); // 移除 "banana"
array_pop函数的实现
/* {{{ Pops an element off the end of the array */
PHP_FUNCTION(array_pop)
{
zval *stack, /* Input stack */
*val; /* Value to be popped */
uint32_t idx;
ZEND_PARSE_PARAMETERS_START(1, 1)
Z_PARAM_ARRAY_EX(stack, 0, 1)
ZEND_PARSE_PARAMETERS_END();
if (zend_hash_num_elements(Z_ARRVAL_P(stack)) == 0) {
return;
}
if (HT_IS_PACKED(Z_ARRVAL_P(stack))) {
/* Get the last value and copy it into the return value */
idx = Z_ARRVAL_P(stack)->nNumUsed;
while (1) {
if (idx == 0) {
return;
}
idx--;
val = Z_ARRVAL_P(stack)->arPacked + idx;
if (Z_TYPE_P(val) != IS_UNDEF) {
break;
}
}
RETVAL_COPY_DEREF(val);
if (idx == (Z_ARRVAL_P(stack)->nNextFreeElement - 1)) {
Z_ARRVAL_P(stack)->nNextFreeElement = Z_ARRVAL_P(stack)->nNextFreeElement - 1;
}
/* Delete the last value */
zend_hash_packed_del_val(Z_ARRVAL_P(stack), val);
} else {
Bucket *p;
/* Get the last value and copy it into the return value */
idx = Z_ARRVAL_P(stack)->nNumUsed;
while (1) {
if (idx == 0) {
return;
}
idx--;
p = Z_ARRVAL_P(stack)->arData + idx;
val = &p->val;
if (Z_TYPE_P(val) != IS_UNDEF) {
break;
}
}
RETVAL_COPY_DEREF(val);
if (!p->key && (zend_long)p->h == (Z_ARRVAL_P(stack)->nNextFreeElement - 1)) {
Z_ARRVAL_P(stack)->nNextFreeElement = Z_ARRVAL_P(stack)->nNextFreeElement - 1;
}
/* Delete the last value */
zend_hash_del_bucket(Z_ARRVAL_P(stack), p);
}
zend_hash_internal_pointer_reset(Z_ARRVAL_P(stack));
}
/* }}} */
队列
$queue = [];
// 入队
array_push($queue, "apple");
array_push($queue, "banana");
// 出队
$item = array_shift($queue); // 移除 "apple"
array_shift函数的实现
/* {{{ Pops an element off the beginning of the array */
PHP_FUNCTION(array_shift)
{
zval *stack, /* Input stack */
*val; /* Value to be popped */
uint32_t idx;
ZEND_PARSE_PARAMETERS_START(1, 1)
Z_PARAM_ARRAY_EX(stack, 0, 1)
ZEND_PARSE_PARAMETERS_END();
if (zend_hash_num_elements(Z_ARRVAL_P(stack)) == 0) {
return;
}
/* re-index like it did before */
if (HT_IS_PACKED(Z_ARRVAL_P(stack))) {
uint32_t k = 0;
/* Get the first value and copy it into the return value */
idx = 0;
while (1) {
if (idx == Z_ARRVAL_P(stack)->nNumUsed) {
return;
}
val = Z_ARRVAL_P(stack)->arPacked + idx;
if (Z_TYPE_P(val) != IS_UNDEF) {
break;
}
idx++;
}
RETVAL_COPY_DEREF(val);
/* Delete the first value */
zend_hash_packed_del_val(Z_ARRVAL_P(stack), val);
if (EXPECTED(!HT_HAS_ITERATORS(Z_ARRVAL_P(stack)))) {
for (idx = 0; idx < Z_ARRVAL_P(stack)->nNumUsed; idx++) {
val = Z_ARRVAL_P(stack)->arPacked + idx;
if (Z_TYPE_P(val) == IS_UNDEF) continue;
if (idx != k) {
zval *q = Z_ARRVAL_P(stack)->arPacked + k;
ZVAL_COPY_VALUE(q, val);
ZVAL_UNDEF(val);
}
k++;
}
} else {
uint32_t iter_pos = zend_hash_iterators_lower_pos(Z_ARRVAL_P(stack), 0);
for (idx = 0; idx < Z_ARRVAL_P(stack)->nNumUsed; idx++) {
val = Z_ARRVAL_P(stack)->arPacked + idx;
if (Z_TYPE_P(val) == IS_UNDEF) continue;
if (idx != k) {
zval *q = Z_ARRVAL_P(stack)->arPacked + k;
ZVAL_COPY_VALUE(q, val);
ZVAL_UNDEF(val);
if (idx == iter_pos) {
zend_hash_iterators_update(Z_ARRVAL_P(stack), idx, k);
iter_pos = zend_hash_iterators_lower_pos(Z_ARRVAL_P(stack), iter_pos + 1);
}
}
k++;
}
}
Z_ARRVAL_P(stack)->nNumUsed = k;
Z_ARRVAL_P(stack)->nNextFreeElement = k;
} else {
uint32_t k = 0;
int should_rehash = 0;
Bucket *p;
/* Get the first value and copy it into the return value */
idx = 0;
while (1) {
if (idx == Z_ARRVAL_P(stack)->nNumUsed) {
return;
}
p = Z_ARRVAL_P(stack)->arData + idx;
val = &p->val;
if (Z_TYPE_P(val) != IS_UNDEF) {
break;
}
idx++;
}
RETVAL_COPY_DEREF(val);
/* Delete the first value */
zend_hash_del_bucket(Z_ARRVAL_P(stack), p);
for (idx = 0; idx < Z_ARRVAL_P(stack)->nNumUsed; idx++) {
p = Z_ARRVAL_P(stack)->arData + idx;
if (Z_TYPE(p->val) == IS_UNDEF) continue;
if (p->key == NULL) {
if (p->h != k) {
p->h = k++;
should_rehash = 1;
} else {
k++;
}
}
}
Z_ARRVAL_P(stack)->nNextFreeElement = k;
if (should_rehash) {
zend_hash_rehash(Z_ARRVAL_P(stack));
}
}
zend_hash_internal_pointer_reset(Z_ARRVAL_P(stack));
}
双端队列
$deque = [];
// 从尾部入队
array_push($deque, "tomato");
// 从头部入队
array_unshift($deque, "apple");
// 从头部出队
$item = array_shift($deque); // 移除 "apple"
// 从尾部出队
$item = array_pop($deque); // 移除 "tomato"
Hash冲突之开发地址法
当关键字 key 的哈希地址 p 出现冲突时,以 p 为基础,产生另一个哈希地址 p1,如果 p1 仍然冲突,再以 p 为基础,产生另一个哈希地址 p2,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。简单地说,开放寻址法的核心思想就是,如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。
关于开放地址探测新位置的方法有:线性探测法、二次探测法、双重哈希法(也叫再哈希法)。
- 线性探测法:当往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。
- 二次探测法:二次探测,跟线性探测很像,只是步长是二次方,线性探测步长是 1。
- 双重哈希法:先用第一个散列函数,如果计算得到的存储位置已经被占用,再用第二个散列函数,依次类推,直到找到空闲的存储位置。
优点
- 散列表中的数据都存储在数组中,可以有效地利用 CPU 缓存加快查询速度;
- 使用数组存储数据,序列化起来比较简单。
缺点
- 开放地址法构造的散列表,删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填入散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点;
- 所有的数据都存储在一个数组中,比起链表法来说,冲突的代价更高。
Hash冲突之链表法
相应的链表法的优缺点如下:
优点
- 拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
- 由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
- 拉链法中负载因子可以根据节点大小进行取值,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
- 用拉链法构造的散列表中,删除结点的操作易于实现,只要简单地删去链表上相应的结点即可。
缺点
- 指针需要额外的空间,故当结点规模较小时,开放地址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放地址法中的冲突,从而提高平均查找速度。